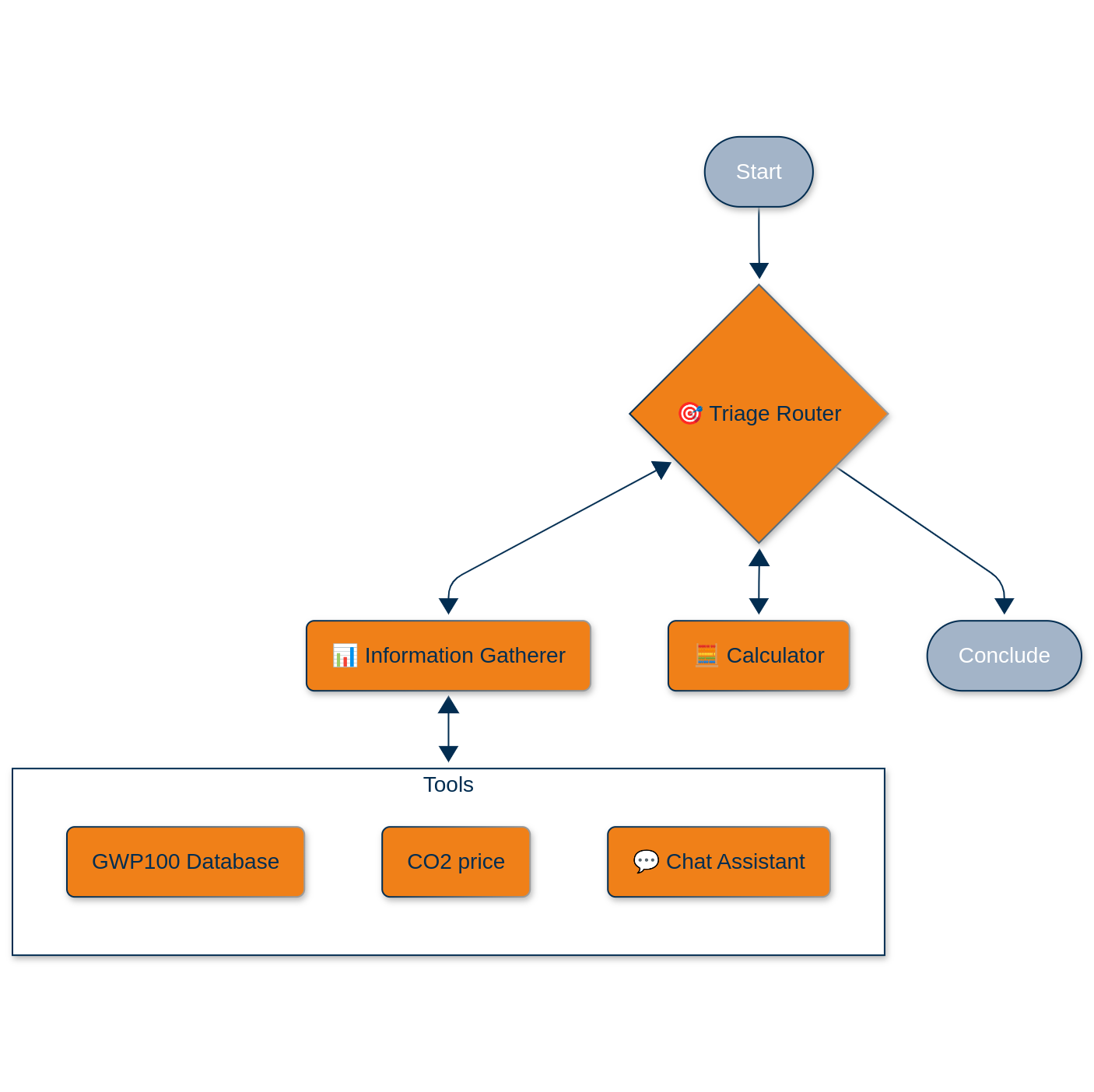
Aufbau eines leichtgewichtigen agentenbasierten Workflows
Anwendungsfall für die reale Welt: Schätzung des CO2-Fußabdrucks mithilfe von KI (!)
TL;DR für nicht-technische Leser
Wir haben ein intelligentes, interaktives System entwickelt, mit dem sich der Kohlenstoff-Fußabdruck von Chemikalien schnell abschätzen lässt. Anstatt komplizierte Formulare auszufüllen, können Sie einfach Fragen eingeben (z. B. nach den CO₂-Emissionen beim Versand von Chemikalien). Das System nutzt fortschrittliche KI, um Ihre Anfrage zu verstehen, sammelt die benötigten Daten (und chattet bei Bedarf sogar mit Ihnen) und berechnet die genauen Ergebnisse auf transparente Weise. Dieser Ansatz verbindet menschenfreundliche Interaktionen mit zuverlässigen Zahlen und sorgt für klare und vertrauenswürdige Schätzungen.
Probieren Sie es selbst aus! Während sich das System noch im Aufbau befindet, können Sie den Prototyp live testen unter https://agents.lyfx.ai. Rechnen Sie mit ein paar Ecken und Kanten, während wir den Arbeitsablauf weiter ausbauen und verfeinern.
Ich habe schon lange gelernt, dass die Kluft zwischen "wir müssen etwas berechnen" und "wir haben ein System, das tatsächlich funktioniert" oft komplexer ist, als man zunächst erwartet. Als wir uns daran machten, einen schnellen Schätzer erster Ordnung für die Treibhausgasemissionen einer beliebigen Chemikalie von der Wiege bis zur Bahre zu erstellen, dachte ich: "Wie schwer kann das schon sein? "Wie schwer kann das schon sein? Es ist doch nur eine einfache Tabellenkalkulation, oder?"
Nun, es hat sich herausgestellt, dass man etwas Intelligenteres als eine Tabellenkalkulation braucht, wenn man möchte, dass die Nutzer Freiform-Anfragen wie "Wie hoch ist der CO₂-Fußabdruck von 50 Tonnen Aceton, die 200 km weit transportiert werden?" eingeben, anstatt starre Formulare auszufüllen. Hier kommen sie ins Spiel: agentische Workflows.
Ich habe mit verschiedenen Ansätzen zur Erstellung von Agenten-Workflows experimentiert (von benutzerdefinierten Orchestrierungsschichten bis hin zu anderen Frameworks), aber LangGraph hat sich als die robusteste Lösung für diese Art von hybrider Mensch-KI-Interaktion erwiesen. Es handhabt Zustandsmanagement, Unterbrechungen und komplexe Routing-Muster mit der Art von Zuverlässigkeit, die man braucht, wenn man etwas baut, das die Menschen tatsächlich benutzen werden.
Die Architektur: Orchestriertes Chaos
Unser System geht von einem vereinfachten Lebenszyklus aus: Produktion an einem einzigen Standort, Transport zum Verwendungsort und teilweise oder vollständige Freisetzung in die Atmosphäre. Die Magie liegt jedoch in der Art und Weise, wie wir die komplizierte Interaktion zwischen Mensch und KI handhaben, die zur Erfassung der erforderlichen Parameter erforderlich ist.
Das haben wir gebaut mit LangGraph als unsere Orchestrierungs-Engine, eingewickelt in eine Django Anwendung serviert über uvicorn und nginx:
Der Triage-Router-Agent
Dies ist der Dirigent unseres kleinen Orchesters. Es verwendet OpenAIs GPT-4o mit strukturierten Ausgaben (Pydantic-Modelle, weil Typsicherheit auch im Zeitalter von LLMs wichtig ist), um eingehende Anfragen zu klassifizieren:
class TriageRouter(BaseModel):
reasoning: str = Field(description="Schrittweise Begründung der Klassifizierung.")
classification: Literal["Informationen sammeln", "berechnen", "antworten und schließen"]
response: str = Field(description="Antwort auf die Anfrage des Benutzers")Der Triage-Agent entscheidet, ob wir weitere Informationen benötigen, bereit sind zu rechnen oder eine Antwort geben können. Er ist im Wesentlichen ein Zustandsautomat mit einem LLM-Gehirn.
Der Informationssammler-Agent
An dieser Stelle wird es interessant. Der Agent ist ein Hybrid. Er kann entweder programmatisch Tools aufrufen oder zu einem interaktiven Chat-Agenten weiterleiten, wenn er menschliche Eingaben benötigt. Die verfügbaren Tools sind:
GWP-Datenbank-Tool: Anstatt eine statische Nachschlagetabelle zu führen, haben wir eine LLM-gestützte "Datenbank" aufgebaut, die unser chemisches Inventar mit über 200 Einträgen durchsucht. Wenn Sie nach dem GWP-100 von Methan fragen, führt es nicht nur einen String-Abgleich durch; es versteht, dass "CH₄" und "Methan" sich auf dasselbe Molekül beziehen. Das Tool gibt eine Klassifizierung (gefunden/eindeutig/nicht verfügbar) sowie den tatsächlichen GWP-Wert zurück.
CO₂-Preis-Checker: Derzeit ein Platzhalter, der 0,5 €/Tonne liefert (wir bauen schrittweise auf!), aber so konzipiert, dass er mit einer Echtzeit-API ausgetauscht werden kann.
Interaktive Chat-Fähigkeit: Wenn der Informationssammler nicht das bekommt, was er von den Tools braucht, übergibt er nahtlos an einen Chat-Agenten. Dabei handelt es sich nicht um eine einfache Übergabe: Wir verwenden den NodeInterrupt-Mechanismus von LangGraph, um den Arbeitsablauf anzuhalten, Benutzereingaben zu sammeln und dann genau dort fortzusetzen, wo wir aufgehört haben.
Der Rechenknecht
Dies ist der einzige Agent, der wirklich rechnet, und zwar ganz bewusst. Er ist ein ReAct-Agent, der mit zwei Rechenwerkzeugen ausgestattet ist:
@tool
def chemikalien_emissions_berechnung(
chemie_name: str,
jährliches_Volumen_t: float,
produktionsfußabdruck_pro_ton: float,
Transport: list[dict],
Freisetzung_in_die_Atmosphäre_ton_p_a: float,
gwp_100: Fließkomma
) -> tuple[str, float]:Der Transportparameter akzeptiert eine Liste von Logistikschritten: [{'step':'production to warehouse', 'distance_km':50, 'mode':'road'}, {'step':'warehouse to port', 'distance_km':250, 'mode':'rail'}]. Jeder Verkehrsträger hat fest kodierte Emissionsfaktoren (Straße: 0.00014, Bahn: 0.000015, Schiff: 0,000136, Luft: 0,0005 Tonnen CO₂e pro Tonnenkilometer), die aus Daten der EUA stammen.
Die Rechnung ist bewusst einfach: Produktionsemissionen, Transportemissionen und die Auswirkungen auf die Atmosphäre, die jeweils deterministisch berechnet werden, werden addiert.
Der technische Stapel: LangGraph + Django
Unser System nutzt den StateGraph von LangGraph zusammen mit einer benutzerdefinierten State-Klasse, um den Gesprächskontext, die gesammelten Daten und die Routing-Informationen bei der Übergabe von Agenten an andere zu erhalten. Während der Entwicklung verwenden wir MemorySaver für die In-Memory-Persistenz, aber für Produktionsumgebungen mit mehreren uvicorn-Workern werden wir zu SqliteSaver mit plattenbasierten Checkpoints wechseln.
Jeder Agent liefert Antworten über Pydantic-Modelle, was Typsicherheit bietet und die typischen LLM-Halluzinationsprobleme bei Routing-Entscheidungen abmildert. Wenn der Triage-Agent beschließt, "zu berechnen", gibt er genau diese Zeichenfolge zurück und nicht Variationen wie "Berechnen" oder "Zeit zu berechnen".
Der Chat-Agent enthält die Funktion NodeInterrupt, um Arbeitsabläufe zu unterbrechen, wenn Benutzereingaben erforderlich sind. Der Status verfolgt über das caller_node-Feld, welcher Agent den Chat initiiert hat, und gewährleistet so eine ordnungsgemäße Weiterleitung nach der Informationssammlung. Der gesamte Workflow läuft innerhalb einer Django-Anwendung, was uns die Flexibilität gibt, Benutzerauthentifizierung, Datenpersistenz und API-Endpunkte hinzuzufügen, wenn sich die Anforderungen weiterentwickeln. Wir verwenden uvicorn für asynchrone Funktionen und nginx für die Produktionszuverlässigkeit.
Mehrere Schlüsselfunktionen befinden sich noch in der Entwicklung. Wenn das System den Treibhausgas-Fußabdruck pro Tonne der Produktion einer Chemikalie benötigt, fragt es derzeit einfach den Benutzer. Dies ist eine vorübergehende Lösung, während wir eine umfassende Datenbank der Produktionswege und der damit verbundenen Emissionen aufbauen. Betrachten Sie es als eine anspruchsvollere Version dessen, was SimaPro oder GaBi bieten, aber speziell auf Chemikalien ausgerichtet und über eine API zugänglich.
Wir planen auch die Integration von Echtzeit-Datenfeeds für CO₂-Preise, Versandrouten und chemische Eigenschaften über Live-APIs. Unsere Priorität liegt jedoch zunächst auf der Orchestrierungsschicht. Sobald das Fundament solide ist, werden wir diese echten Datenquellen einbinden.
Ein weiterer verbesserungswürdiger Bereich ist der Konversationsspeicher. Derzeit beginnt jede Berechnung bei Null, aber das Hinzufügen von Sitzungspersistenz, um frühere Abfragen zu speichern und darauf aufzubauen, wird angesichts unserer aktuellen Architektur einfach sein.
Diese Architektur ist ein hervorragender Ausgangspunkt, da sie eine klare Trennung der Belange beibehält. LLMs übernehmen die unübersichtliche menschliche Interaktion und die Routing-Logik, während Python-Funktionen die deterministischen Berechnungen verwalten. Das bedeutet, dass Fachexperten die mathematischen Komponenten validieren und ändern können, ohne den KI-Stack anfassen zu müssen.
Die Workflows bleiben dank der Zustandsverwaltung von LangGraph hochgradig debuggingfähig, so dass Sie genau überprüfen können, was jeder Agent entschieden hat und warum. Wenn etwas schief geht, müssen Sie nicht eine Blackbox debuggen. Das System unterstützt auch eine zunehmende Komplexität - Sie können mit fest kodierten Werten beginnen, nach und nach Datenbankabfragen hinzufügen und dann Echtzeit-APIs integrieren, während die Kernstruktur des Workflows intakt bleibt.
Am wichtigsten ist vielleicht, dass jeder Berechnungsschritt durch die LangSmith-Protokollierung überprüfbar wird. Wenn jemand unweigerlich fragt: "Woher kommen diese 142,7 Tonnen CO₂e?", können Sie ihm die genauen Eingaben und die verwendete Formel zeigen und so einen vollständigen Prüfpfad von der Frage bis zum Endergebnis erstellen.
Das größere Bild
Hier geht es nicht nur um den CO2-Fußabdruck. Das Muster - Verwendung von LLMs für das Verstehen natürlicher Sprache und die Orchestrierung von Arbeitsabläufen, aber Beibehaltung der kritischen Berechnungen in deterministischem Code - gilt für jeden Bereich, in dem Sie weiche Argumente mit harten Zahlen kombinieren müssen.
Risikobewertung der Lieferkette? Gleiches Muster. Finanzmodellierung mit Einhaltung von Vorschriften? Gleiches Muster. Jedes Mal, wenn Sie sich fragen: "Wir brauchen eine intelligente Schnittstelle zu unseren bestehenden Berechnungen", bietet Ihnen diese Architektur einen Ausgangspunkt.
Die Zukunft liegt in der hybriden Intelligenz, nicht darin, alles auf einen LLM zu werfen und auf das Beste zu hoffen.
Entwickelt in Python mit LangGraph, OpenAI APIs, Django. Co-programmiert mit Claude Sonnet 3.7 und 4, Chat GPT o3 (nicht "vibe coded"). Derzeit in aktiver Entwicklung. Probieren Sie es aus unter https://agents.lyfx.ai.