Criar um fluxo de trabalho agêntico leve
Caso de utilização para o mundo real: Estimar as pegadas de carbono utilizando a IA (!)
TL;DR para leitores não técnicos
Criámos um sistema inteligente e interativo para calcular rapidamente a pegada de carbono dos produtos químicos. Em vez de preencher formulários complicados, pode simplesmente escrever perguntas de forma natural (como perguntar as emissões de CO₂ do transporte de produtos químicos). O sistema utiliza IA avançada para compreender o seu pedido, recolhe os dados necessários (mesmo conversando consigo, se necessário) e calcula resultados precisos de forma transparente. Esta abordagem combina interações amigáveis com números fiáveis, garantindo estimativas claras e fiáveis.
Experimente-o você mesmo! Enquanto este sistema está "em construção", pode testar o protótipo em direto em https://agents.lyfx.ai. Espere algumas arestas à medida que continuamos a construir e a aperfeiçoar o fluxo de trabalho.
Há muito que aprendi que o intervalo entre "precisamos de calcular algo" e "temos um sistema que funciona de facto" é frequentemente preenchido com mais complexidade do que alguém inicialmente espera. Quando nos propusemos construir um estimador rápido de primeira ordem para as emissões de gases com efeito de estufa de qualquer produto químico do início ao fim do processo, pensei: "Será assim tão difícil? É apenas uma simples folha de cálculo, certo?"
Bem, acontece que quando se pretende que os utilizadores introduzam pedidos de forma livre como "qual é a pegada de CO₂ de 50 toneladas de acetona transportadas a 200 km?" em vez de preencherem formulários rígidos, é necessário algo mais inteligente do que uma folha de cálculo. Eis os fluxos de trabalho agênticos.
Experimentei várias abordagens para criar fluxos de trabalho de agentes (desde camadas de orquestração personalizadas a outras estruturas), mas o LangGraph surgiu como a solução mais robusta para este tipo de interação híbrida homem-IA. Lida com a gestão do estado, interrupções e padrões de encaminhamento complexos com o tipo de fiabilidade de que se precisa quando se constrói algo que as pessoas vão realmente usar.
A Arquitetura: Caos Orquestrado
O nosso sistema pressupõe um ciclo de vida simplificado: produção num único local, transporte até ao ponto de utilização e libertação atmosférica parcial ou total. Mas a magia está na forma como lidamos com a confusa interação homem-IA necessária para reunir os parâmetros exigidos.
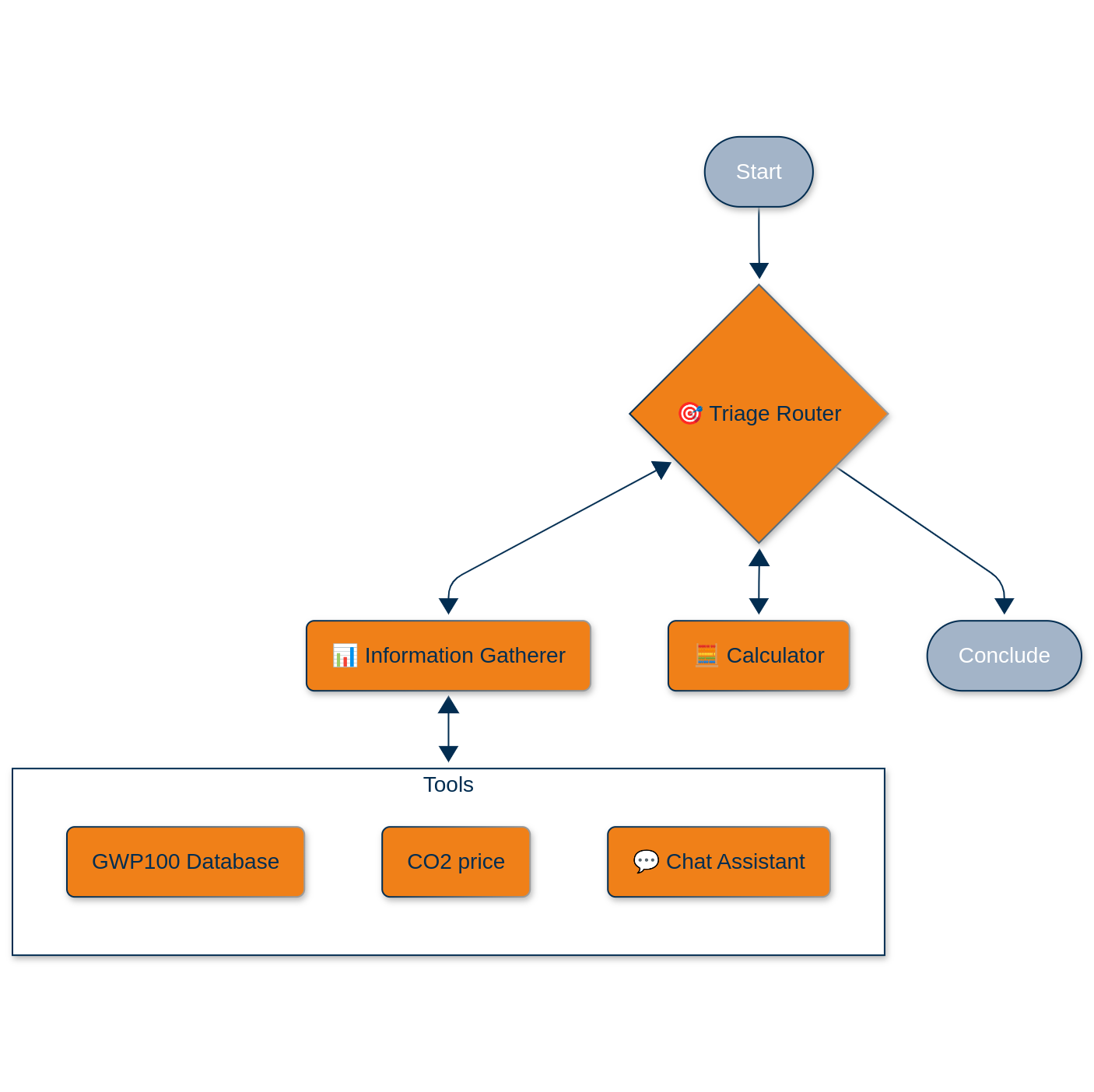
Eis o que construímos utilizando LangGraph como nosso mecanismo de orquestração, envolto em um Django aplicação servida via uvicórnio e nginx:
O agente do encaminhador de triagem
Este é o maestro da nossa pequena orquestra. Utiliza o GPT-4o da OpenAI com saídas estruturadas (modelos Pydantic, porque a segurança de tipos é importante mesmo na era dos LLMs) para classificar os pedidos recebidos:
class TriageRouter(BaseModel):
reasoning: str = Field(description="Raciocínio passo a passo por detrás da classificação.")
classificação: Literal["recolher informação", "calcular", "responder e concluir"]
resposta: str = Field(description="Resposta ao pedido do utilizador")O agente de triagem decide se precisamos de mais informações, se estamos prontos para calcular ou se podemos concluir com uma resposta. É essencialmente uma máquina de estados com um cérebro LLM.
O agente de recolha de informações
É aqui que as coisas se tornam interessantes. O agente é híbrido. Pode chamar ferramentas de forma programática ou encaminhar para um agente de conversação interactiva quando necessita de intervenção humana. As ferramentas disponíveis são:
Ferramenta da base de dados GWP: Em vez de manter uma tabela de pesquisa estática, construímos uma "base de dados" alimentada por LLM que pesquisa o nosso inventário químico com mais de 200 entradas. Quando se pede o GWP-100 do metano, a ferramenta não se limita a fazer uma correspondência de cadeias de caracteres; compreende que "CH₄" e "metano" se referem à mesma molécula. A ferramenta devolve uma classificação (encontrado/ambíguo/não disponível) mais o valor real do GWP.
Verificador de preços CO₂: Atualmente, um espaço reservado que devolve 0,5 €/tonelada (estamos a construir gradualmente!), mas concebido para ser trocado por uma API em tempo real.
Capacidade de conversação interactiva: Quando o coletor de informação não consegue obter o que precisa a partir das ferramentas, passa sem problemas para um agente de chat. Não se trata de uma simples transferência: usamos o mecanismo NodeInterrupt do LangGraph para fazer uma pausa no fluxo de trabalho, recolher os dados do utilizador e depois retomar exatamente onde parámos.
O agente calculador
Este é o único agente que faz cálculos reais, e deliberadamente. É um agente ReAct equipado com duas ferramentas de cálculo:
@ferramenta
def chemicals_emission_calculator(
nome_do_produto_químico: str,
volume_anual_ton: float,
pegada_de_produção_por_tonelada: float,
transporte: list[dict],
libertação_para_a_atmosfera_ton_p_a: float,
gwp_100: float
) -> tuple[str, float]:O parâmetro de transporte aceita uma lista de etapas logísticas: [{'step':'production to warehouse', 'distance_km':50, 'mode':'road'}, {'step':'warehouse to port', 'distance_km':250, 'mode':'rail'}]. Cada modo tem factores de emissão codificados (rodoviário: 0,00014, comboio: 0,000015, navio: 0,000136, ar: 0,0005 tonelada de CO₂e por tonelada-km) provenientes de dados da AEA.
A matemática é intencionalmente simples: somar as emissões da produção, as emissões do transporte e os impactos da libertação na atmosfera, cada um calculado de forma determinística.
A pilha técnica: LangGraph + Django
Nosso sistema aproveita o StateGraph do LangGraph junto com uma classe de estado personalizada para manter o contexto da conversa, os dados coletados e as informações de roteamento à medida que os agentes passam uns para os outros. Durante o desenvolvimento, contamos com o MemorySaver para persistência na memória, mas faremos a transição para o SqliteSaver com pontos de verificação baseados em disco para ambientes de produção que executam vários workers uvicorn.
Cada agente fornece respostas através de modelos Pydantic, o que proporciona segurança de tipo e atenua os problemas típicos de alucinação LLM em torno de decisões de encaminhamento. Quando o agente de triagem decide "calcular", devolve exatamente essa cadeia de caracteres em vez de variações como "Calcular" ou "tempo para calcular".
O agente de conversação incorpora a funcionalidade NodeInterrupt para fazer uma pausa nos fluxos de trabalho quando é necessária a entrada do utilizador. O estado rastreia qual agente iniciou o chat através do campo caller_node, garantindo o encaminhamento adequado após a coleta de informações. Todo o fluxo de trabalho funciona dentro de uma aplicação Django, o que nos dá a flexibilidade de adicionar autenticação de utilizador, persistência de dados e pontos finais de API à medida que os requisitos evoluem. Servimos tudo através de uvicorn para capacidades assíncronas e nginx para fiabilidade de produção.
Várias caraterísticas-chave ainda estão a ser desenvolvidas. Atualmente, quando o sistema necessita da pegada de GEE por tonelada de produção de um produto químico, basta perguntar ao utilizador. Esta é uma solução temporária enquanto construímos uma base de dados abrangente de rotas de produção e das suas emissões associadas. Pense nisto como uma versão mais sofisticada do que o SimaPro ou o GaBi oferecem, mas especificamente focada em produtos químicos e acessível através de uma API.
Também estamos a planear integrar feeds de dados em tempo real para preços de CO₂, rotas de transporte e propriedades químicas através de APIs em tempo real. No entanto, estamos priorizando a camada de orquestração primeiro, depois trocaremos essas fontes de dados reais quando a base estiver sólida.
Outra área a melhorar é a memória de conversação. Atualmente, cada cálculo começa do zero, mas a adição de persistência de sessão para recordar consultas anteriores e construir sobre elas será simples, dada a nossa arquitetura atual.
Esta arquitetura serve como um excelente ponto de partida porque mantém uma clara separação de preocupações. Os LLMs tratam da interação humana confusa e da lógica de encaminhamento, enquanto as funções Python gerem os cálculos determinísticos. Isto significa que os especialistas do domínio podem validar e modificar os componentes matemáticos sem terem de tocar na pilha de IA.
Os fluxos de trabalho permanecem altamente depuráveis graças à gestão do estado do LangGraph, que lhe permite inspecionar exatamente o que cada agente decidiu e porquê. Quando algo corre mal, não fica preso a depurar uma caixa negra. O sistema também suporta a complexidade incremental - pode começar com valores codificados, adicionar gradualmente pesquisas na base de dados e depois integrar APIs em tempo real, tudo isto mantendo intacta a estrutura central do fluxo de trabalho.
Talvez o mais importante seja o facto de cada passo do cálculo ser auditável através do registo LangSmith. Quando alguém inevitavelmente pergunta "de onde vieram essas 142,7 toneladas de CO₂e?", você pode mostrar a eles as entradas exatas e a fórmula usada, criando uma trilha de auditoria completa desde a pergunta até o resultado final.
O quadro geral
Não se trata apenas de pegadas de carbono. O padrão - utilizar LLMs para a compreensão da linguagem natural e a orquestração do fluxo de trabalho, mas manter os cálculos críticos em código determinístico - aplica-se a qualquer domínio em que seja necessário misturar raciocínio suave com números difíceis.
Avaliação dos riscos da cadeia de abastecimento? O mesmo padrão. Modelação financeira com conformidade regulamentar? O mesmo padrão. Sempre que pensar "precisamos de uma interface inteligente para os nossos cálculos existentes", esta arquitetura dá-lhe um ponto de partida.
O futuro é a inteligência híbrida, e não apenas o facto de se apostar tudo num LLM e esperar pelo melhor.
Construído em Python com LangGraph, APIs OpenAI, Django. Co-programado usando Claude Sonnet 3.7 e 4, Chat GPT o3 (não "vibe coded"). Atualmente em desenvolvimento ativo. Experimente em https://agents.lyfx.ai.