Creación de un flujo de trabajo agenético ligero
Caso práctico para el mundo real: Estimación de la huella de carbono mediante IA (¡!)
TL;DR para lectores no técnicos
We built a smart, interactive system to quickly estimate the carbon footprint of chemicals. Instead of filling out complicated forms, you can just type questions naturally (like asking the CO₂ emissions of shipping chemicals). The system uses advanced AI to understand your request, gathers the needed data (even chatting with you if necessary), and calculates accurate results transparently. This approach blends human-friendly interactions with reliable numbers, ensuring clear and trustworthy estimates.
Try it yourself! While this system is “under construction”, you can test the live prototype at https://agents.lyfx.ai. A medida que vayamos desarrollando y perfeccionando el flujo de trabajo, iremos encontrando algunas asperezas.
I have long learned that the gap between “we need to calculate something” and “we have a system that actually works” is often filled with more complexity than anyone initially expects. When we set out to build a quick first-order estimator for cradle-to-gate greenhouse gas emissions of any chemical, I thought: “How hard can it be? it is just a simple spreadsheet, right?”
Well, it turns out that when you want users to input free-form requests like “what is the CO₂ footprint of 50 tonnes of acetone shipped 200 km?” instead of filling out rigid forms, you need something smarter than a spreadsheet. Enter: agentic workflows.
He experimentado con varios enfoques para la construcción de flujos de trabajo de agentes (desde capas de orquestación personalizadas a otros marcos), pero LangGraph ha surgido como la solución más robusta para este tipo de interacción híbrida humano-AI. Maneja la gestión de estados, interrupciones y patrones de enrutamiento complejos con el tipo de fiabilidad que se necesita cuando se construye algo que la gente realmente va a utilizar.
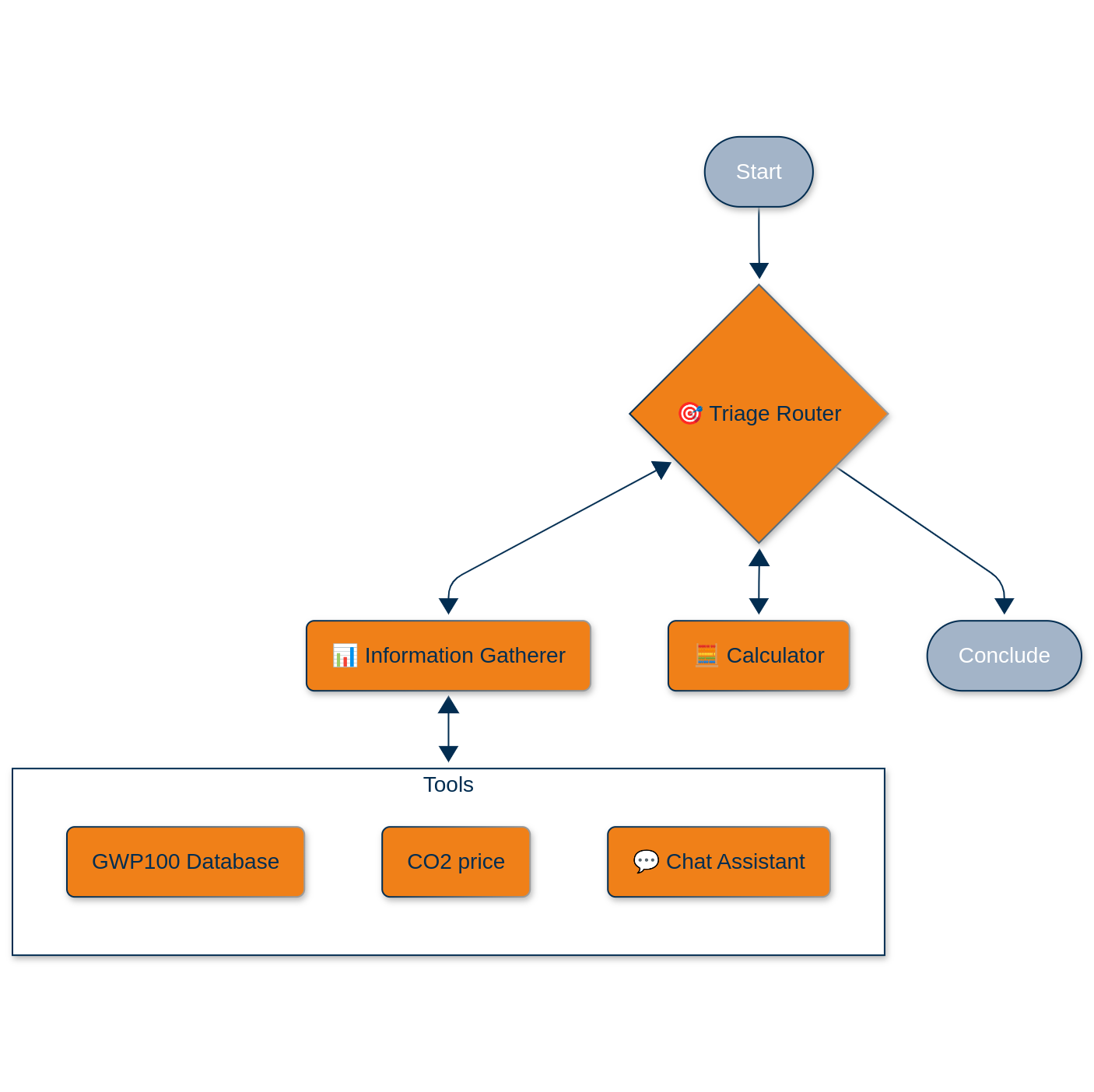
La arquitectura: Caos orquestado
Nuestro sistema parte de un ciclo de vida simplificado: producción en un único lugar, transporte hasta el punto de uso y liberación parcial o total en la atmósfera. Pero la magia está en cómo gestionamos la complicada interacción entre el ser humano y la inteligencia artificial necesaria para reunir los parámetros requeridos.
Here’s what we built using LangGraph como nuestro motor de orquestación, envuelto en un Django solicitud servida a través de uvicornio y nginx:
El agente de enrutamiento de triaje
This is the conductor of our little orchestra. It uses OpenAI’s GPT-4o with structured outputs (Pydantic models, because type safety matters even in the age of LLMs) to classify incoming requests:
class TriageRouter(BaseModel):
reasoning: str = Field(description="Step-by-step reasoning behind the classification.")
classification: Literal["gather information", "calculate", "respond and conclude"]
response: str = Field(description="Response to user's request")El agente de triaje decide si necesitamos más información, si estamos listos para calcular o si podemos concluir con una respuesta. es esencialmente una máquina de estados con un cerebro LLM.
El agente recopilador de información
Aquí es donde las cosas se ponen interesantes. El agente es híbrido. Puede llamar a herramientas de forma programática o dirigirse a un agente de chat interactivo cuando necesita intervención humana. Las herramientas disponibles son:
Herramienta de base de datos GWP: Instead of maintaining a static lookup table, we built an LLM-powered “database” that searches through our chemical inventory with over 200 entries. When you ask for methane’s GWP-100, it does not just do string matching; it understands that “CH₄” and “methane” refer to the same molecule. The tool returns a classification (found/ambiguous/not available) plus the actual GWP value.
CO₂ Price Checker: Currently a placeholder returning 0.5 €/ton (we are building incrementally!), but designed to be swapped with a real-time API.
Chat interactivo: When the information gatherer cannot get what it needs from tools, it seamlessly hands off to a chat agent. This is not just a simple handoff: we use LangGraph’s NodeInterrupt mechanism to pause the workflow, collect user input, then resume exactly where we left off.
El agente calculista
Se trata de un agente ReAct equipado con dos herramientas de cálculo:
@tool
def chemicals_emission_calculator(
chemical_name: str,
annual_volume_ton: float,
production_footprint_per_ton: float,
transportation: list[dict],
release_to_atmosphere_ton_p_a: float,
gwp_100: float
) -> tuple[str, float]:The transportation parameter accepts a list of logistics steps: [{‘step’:’production to warehouse’, ‘distance_km’:50, ‘mode’:’road’}, {‘step’:’warehouse to port’, ‘distance_km’:250, ‘mode’:’rail’}]. Each mode has hardcoded emission factors (road: 0.00014, rail: 0.000015, ship: 0.000136, air: 0.0005 ton CO₂e per ton·km) sourced from EEA data.
La matemática es intencionadamente sencilla: sumar las emisiones de la producción, las emisiones del transporte y los impactos de la liberación atmosférica, cada uno calculado de forma determinista.
La pila técnica: LangGraph + Django
Our system leverages LangGraph’s StateGraph along with a custom State class to maintain conversation context, collected data, and routing information as agents hand off to each other. During development, we rely on MemorySaver for in-memory persistence, but we’ll transition to SqliteSaver with disk-based checkpoints for production environments running multiple uvicorn workers.
Every agent delivers responses through Pydantic models, which provides type safety and mitigates the typical LLM hallucination problems around routing decisions. When the triage agent decides to “calculate,” it returns exactly that string rather than variations like “Calculate” or “time to calculate.”
El agente de chat incorpora la funcionalidad NodeInterrupt para pausar los flujos de trabajo cuando se requiere la entrada del usuario. El estado rastrea qué agente inició el chat a través del campo caller_node, asegurando el enrutamiento adecuado después de la recopilación de información. Todo el flujo de trabajo funciona dentro de una aplicación Django, lo que nos da flexibilidad para añadir autenticación de usuarios, persistencia de datos y puntos finales de API a medida que evolucionan los requisitos. Servimos todo a través de uvicorn para capacidades asíncronas y nginx para fiabilidad de producción.
Several key features are still in development. Currently, when the system needs the GHG footprint per ton of a chemical’s production, it simply asks the user. This is a temporary solution while we build out a comprehensive database of production routes and their associated emissions. Think of it as a more sophisticated version of what SimaPro or GaBi offers, but specifically focused on chemicals and accessible through an API.
We’re also planning to integrate real-time data feeds for CO₂ prices, shipping routes, and chemical properties through live APIs. However, we’re prioritizing the orchestration layer first, then we’ll swap in these real data sources once the foundation is solid.
Otra área de mejora es la memoria de conversación. Actualmente, cada cálculo parte de cero, pero añadir persistencia de sesión para recordar consultas anteriores y basarse en ellas será sencillo dada nuestra arquitectura actual.
Esta arquitectura es un excelente punto de partida porque mantiene una clara separación de intereses. Los LLM se encargan de la interacción humana y la lógica de enrutamiento, mientras que las funciones de Python gestionan los cálculos deterministas. Esto significa que los expertos del dominio pueden validar y modificar los componentes matemáticos sin necesidad de tocar la pila de IA.
The workflows remain highly debuggable thanks to LangGraph’s state management, which lets you inspect exactly what each agent decided and why. When something goes wrong, you’re not stuck debugging a black box. The system also supports incremental complexity beautifully—you can start with hardcoded values, gradually add database lookups, and then integrate real-time APIs, all while keeping the core workflow structure intact.
Perhaps most importantly, every calculation step becomes auditable through LangSmith logging. When someone inevitably asks “where did that 142.7 tons CO₂e come from?”, you can show them the exact inputs and formula used, creating a complete audit trail from question to final result.
Panorama general
This is not just about carbon footprints. The pattern – use LLMs for natural language understanding and workflow orchestration, but keep the critical calculations in deterministic code – applies to any domain where you need to mix soft reasoning with hard numbers.
Supply chain risk assessment? Same pattern. Financial modeling with regulatory compliance? Same pattern. Any time you find yourself thinking “we need a smart interface to our existing calculations,” this architecture gives you a starting point.
El futuro es la inteligencia híbrida, no simplemente lanzarlo todo en un LLM y esperar lo mejor.
Built in Python with LangGraph, OpenAI APIs, Django. Co-programmed using Claude Sonnet 3.7 and 4, Chat GPT o3 (not “vibe coded”). Currently in active development. Try it at https://agents.lyfx.ai.